BizCrush Case Study: The Unit Ecomics Behind Cutting AI Infrastructure Costs by 64% in 90 Days
7
min

Ethan Kim
Co-founder & CTO
A Reality Check on AI Economics

What does the real world of AI startups look like once the demo buzz fades?
At Columbia Business School, BizCrush CTO Ethan Kim recently shared one simple rule:
Every API call costs money — and the smartest teams build architectures that scale with that truth in mind.
In this post, we’ll unpack how BizCrush redesigned its AI infrastructure and cut monthly costs by 64% in just 90 days, without slowing product performance.
The Hidden Cost Curve of AI Startups
Most early AI products impress fast. But scale flips the economics.
Around 10K monthly active users, every extra API call, retry, or re-run turns into real burn. Optimizing for accuracy alone doesn’t cut it at scale — you need to optimize for result-per-dollar, not cost-per-token.
BizCrush’s meeting agent — which captures in-person conversations, summarizes insights, and auto-generates personalized follow-ups — once triggered dozens of LLM calls per session. Instead of swapping models, the team rethought the architecture.
Building Smarter, Not Bigger
Infrastructure spend was $25K/month.
Three months later, it was ~$9K/month — a 64% drop — driven by changes in *caching, model *routing/mixing, and internal communication processes.
*Caching: Storing and reusing previous model outputs to reduce token and compute spend.
*Routing: Automatically directing each task to the model or server best suited for it.
1. Prompt Caching: Reuse What You Already Paid For
Problem: The system kept re-sending identical prompts, examples, and context blocks for multiple calls.
Solution: Move to a cache-first pipeline.
If a call is cache-eligible, the system reuses previously processed data — no need to pay again for the same tokens.
Why it works: LLMs “remember” through tokens. By caching context, we hold that memory without repurchasing it. Our team measured cache-hit rates (CHR) across providers and standardized around the most efficient setup.
Impact: Fewer input tokens, lighter compute, same quality.
Caching isn’t optional — it’s a core cost layer.
Model | Quality | Hallucination | *Cache Hit Rate | Cost Ratio | Support Cost |
|---|---|---|---|---|---|
GPT-5 mini | ⭐⭐ | High | 12.5% | 0.2 | 2.2 |
GPT-5 | ⭐⭐⭐⭐ | Middle | 12.5% | 1 | 1 |
Claude Sonnet 4.5 | ⭐⭐⭐⭐½ | Low | 80% | 1.02 | 0.2 |
*CHR (Cache Hit Ratio): A metric that shows how often requested data is found in cache memory instead of being recomputed or re-fetched. A higher CHR means greater efficiency and lower processing cost.
2. Model Routing and Mixing: Cheapest Result > Cheapest Token
Not every job needs the same model.
BizCrush routes tasks by type and actual cost per result, not list price.
Complex, repeatable tasks → Claude Sonnet-class models (higher upfront cost, but better cache reuse).
Simple, one-shot calls → Smaller GPT-series models.
Routing adjusts automatically based on quality × latency × *retries.
If a smaller model causes extra retries, it’s not cheaper in the end.
Result: Stable quality, smoother latency, and significantly lower overall spend.
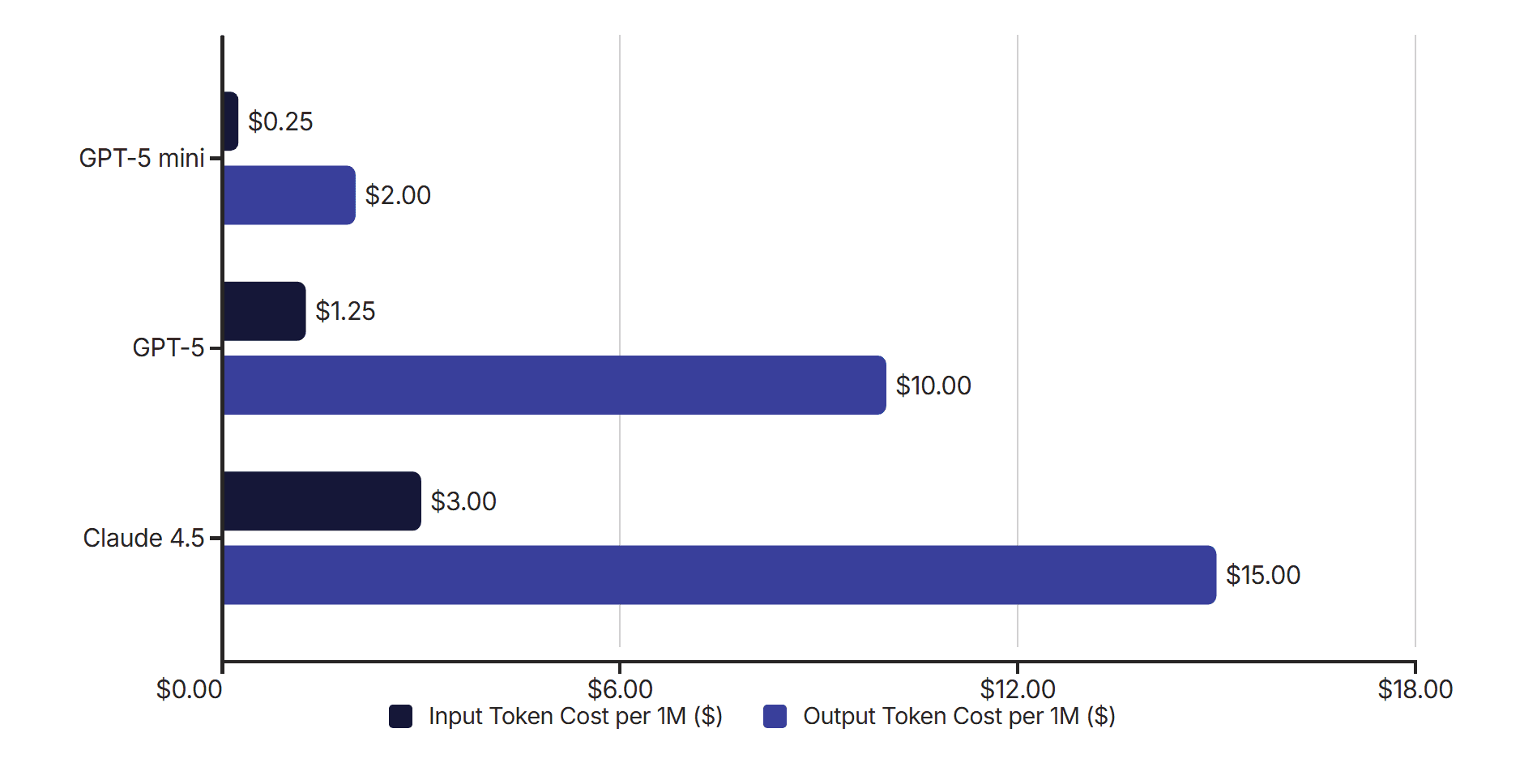
Cheapest token ≠ cheapest outcome.
*Retries: In AI systems, a retry happens when a model’s response fails validation or confidence checks and must be rerun. Each retry adds time and cost to the overall process.
3. Designing for What Models Can’t (Yet) Do
Models are probabilistic, and as such, products must demonstrate predictable behavior.
To prevent uncertainty from spiraling into wasted spend, BizCrush designed the system:
Each task has a confidence level — it won't keep trying if it's uncertain.
Uncertain outputs go to a cheaper validator or *fallback model instead of expensive re-runs.
Cost-Heavy features (like real-time translation) toggle on only when necessary.
Use *HITL (Human-in-the-Loop) for tasks that require accuracy and compliance.
This approach keeps costs predictable while maintaining reliability.
*Fallback model: A secondary model or simplified system that steps in when the primary AI model produces uncertain or low-confidence results.
*HITL (Human-in-the-Loop): A quality-control process where a human briefly reviews or corrects AI outputs, ensuring higher accuracy in critical tasks.
4. Communication Was the Real Bottleneck
During his talk, Ethan asked:
“How many of you built something that didn’t break — but still didn’t work?”
The issue wasn’t code — it was communication.
The BizCrush team aligned PMs and engineers around shared terms: confidence levels, fallback plans, and *cost metrics. Once everyone spoke the same language, decision-making accelerated, and the cost impact of design choices became clear.

*Cost metrics: Standardized measurements for tracking expenses tied to model calls, latency, retries, and compute usage—used to align engineering and product priorities.
The Results: Turning Costs into Confidence
Metric | Before (Naive) | After (Redesigned) |
|---|---|---|
Monthly Infra Cost | ~$25,000 | ~$9,000 (↓64%) |
Economic Lens | “Cheapest token” | “Cheapest result” |
Context Handling | Re-sent scaffolds | Cache-first, CHR-optimized |
Model Policy | Single-model bias | Task-based routing |
Failure Mode | Silent retries | Confidence + fallback + HITL |
Live Features | Always-on | Optional |
Cost Review Cadence | Ad-hoc | Monthly review |
Team habits that stuck:
Measure before debating: Track CHR (cache-hit rate), *retry tax, and per-result cost before arguing which provider or model performs better.
Right-size by task: Assign models like indexes — only where they belong.
Align PM ↔ Eng: Build rules in the specifications so everyone works with the same expectations.
Review pricing regularly: Model costs shift often; treat them like dependencies that need to be reviewed regularly.
*Retry tax: The accumulated financial and performance cost caused by failed or low-confidence AI calls that must be retried to achieve acceptable results.
Profitability as a Feature
Two principles stood out from Ethan’s workshop:
Profitability is an engineering decision. You can design it the same way you design for latency or uptime.
Cheaper outcomes beat cheaper tokens. The only way to learn which is which is by measuring your own data.

At BizCrush, we continue refining how AI infrastructure scales in real-world products. If you’re tackling similar challenges or want to compare notes, we’d love to connect.

