Introducing the BizCrush STT Benchmark
5
min

BizCrush
Growth
Comparing speech-to-text accuracy through actual app workflows
“Which STT service is more accurate?”
It sounds like a simple question, but the answer often depends on the audio, environment, app behavior, and post-processing. Different users experience different conditions, which makes it difficult to compare speech-to-text services based on impressions alone.
BizCrush built this benchmark to make STT results easier to compare under the same conditions.
Instead of testing only recognition engine APIs, the BizCrush Benchmark runs the actual apps users interact with. The same audio is played through the same input path, and the transcripts produced by each app are compared against a reference transcript.
We publish not only the scores, but also the source audio, reference transcript, app-generated transcript, and error analysis so readers can inspect the results directly on the benchmark page.
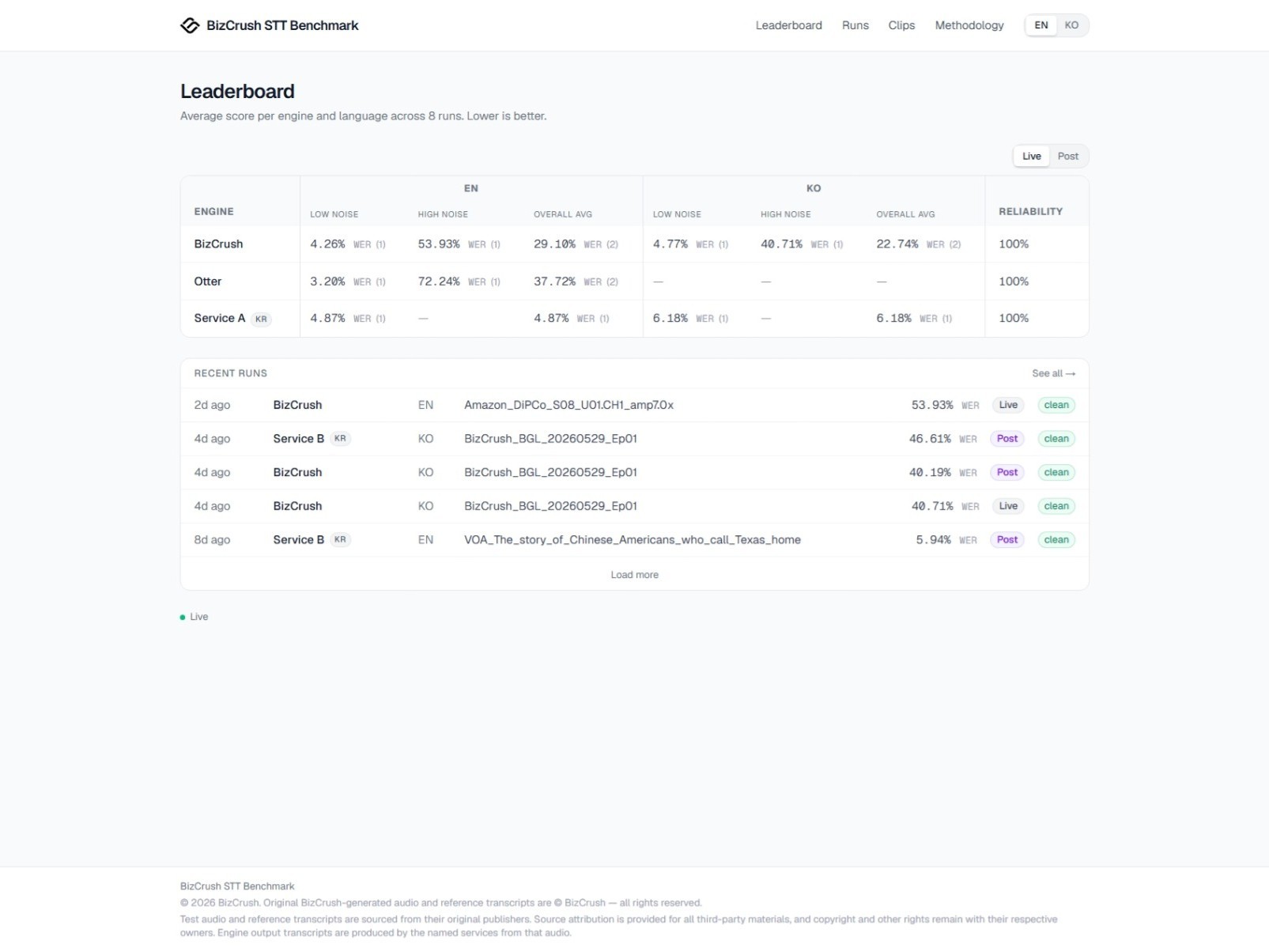
June 12, 2026. Please visit the benchmark page for the latest results.
Why we built it
Many speech-to-text services highlight high accuracy.
But it is often difficult to compare how accurate they are, where they perform well, and where they struggle under the same conditions. In quiet office environments, most services perform reasonably well. The harder cases are the ones users often face in practice: multiple people speaking, background noise, overlapping speech, or speakers at different distances.
BizCrush created this benchmark to compare how STT services perform in these more realistic conditions.
BizCrush is also included in the benchmark. That is why we publish more than just the final score. We also provide the reference transcript, app output, scoring method, and known limitations. When a benchmark includes the company that built it, the results need to be easy to inspect.
What makes this benchmark different?
Most STT benchmarks test recognition engines by calling their APIs directly. That approach is useful for evaluating engine-level performance.
But many users do not experience the engine directly. They experience the full app built around it. Meeting note apps and transcription services often add their own audio handling, noise reduction, formatting, and post-processing on top of the recognition engine. As a result, API performance and the transcript users actually see in the app can differ.
The BizCrush Benchmark is designed to test that app-level path.
We play the reference audio, run the actual STT app in an Android emulator, send the audio through the microphone input path, and collect the transcript generated by the app. That transcript is then compared against the reference transcript.
This does not reproduce every possible real-world variable. Device type, physical microphone quality, room acoustics, network conditions, and app versions can all affect results. What this benchmark provides is a same-condition comparison: the same audio, the same input method, and the same scoring criteria across services.
How the test works
The test follows these steps:
Launch each target app, including BizCrush, and start recording.
Send the reference audio through the microphone input path.
Collect the real-time transcript generated by the app.
Save the final result after playback ends.
Compare the app transcript with the reference transcript and calculate WER or CER.
Review the result manually to separate formatting differences from actual recognition errors before publishing.
All test results go through human review before publication. This review is not used to arbitrarily adjust scores. It is used to check whether differences such as casing, punctuation, spacing, number formatting, or unit formatting were incorrectly counted as recognition errors during automated scoring.
Real-time and post-processed transcripts are reported separately
Many services revise transcripts after recording ends. They may add punctuation, clean up sentence structure, or correct words that were initially recognized incorrectly.
This post-processing can improve the user experience. However, the transcript users see during a live meeting and the transcript they receive after recording ends should be evaluated separately.
That is why BizCrush measures two types of output.
Real-time transcript
This measures what users actually see on screen during a meeting or live recording.
Post-processed transcript
This measures the final transcript after post-processing has been applied.
When a service provides both results, we publish them separately. This makes it easier to see how much post-processing changes the final output. Post-processed results for meeting note and note-taking services are being added gradually.
How scores are calculated
Scores are calculated using WER, or Word Error Rate, and CER, or Character Error Rate. For both metrics, lower numbers indicate higher accuracy.
WER measures the rate of changed, missing, or added words compared with the reference transcript. CER applies the same idea at the character level.
Errors are classified into four categories:
Substitution: a spoken word is recognized as a different word
Deletion: a spoken word is missed
Insertion: a word that was not spoken is added
Correct: the word is recognized correctly
For example, if the reference transcript is:
We have a meeting tomorrow at three.
and the app transcript is:
We have a meeting tomorrow at four.
then “three” has been recognized as “four,” which counts as one substitution error.
In real transcripts, however, there may be differences that are not directly related to speech recognition accuracy. These include casing, punctuation, spacing, number formatting, currency formatting, and unit formatting. For languages where spacing, segmentation, or writing conventions can vary, CER can also provide an additional view alongside WER.
Because these formatting differences can be counted as errors by automated scoring, BizCrush reviews the results after automatic calculation to distinguish formatting differences from actual recognition errors.
The same criteria are applied across all test results. They are not applied selectively to a specific language or service.
Why noisy environments matter
In quiet environments, most services produce strong results. But when there is background noise or when multiple people speak at the same time, the differences between services become much more visible.
That difference matters in real usage.
Meeting rooms, conference halls, cafés, trade shows, lectures, customer interviews, and networking events are rarely silent. A speaker may be far from the microphone. Several people may react at once. Other conversations and background sounds may be present.
The BizCrush Benchmark reflects these conditions by publishing results across different noise conditions. The most important point is not a single score in isolation, but how each service performs with the same audio, the same input path, and the same scoring criteria.
The latest results are available on the benchmark page.
Separating formatting differences from recognition errors
To evaluate speech recognition performance more accurately, formatting differences are separated from actual recognition errors whenever possible.
For example, the following differences are not counted as errors when the meaning is the same:
Casing differences
Punctuation differences
HTML entities
Currency formatting
Percentage formatting
Number formatting
Spacing differences
Different spellings that preserve the same pronunciation and meaning
These cases are reviewed manually. If the difference is not considered an actual recognition error, it is treated as a match.
This process is not applied to favor any particular service. The same criteria are applied to all service results.
What data is published?
The current test set is built around audio that BizCrush has permission to use or that can be inspected publicly on the benchmark page.
Each test detail page includes:
Source audio
Reference transcript
App-generated transcript
Error analysis
WER/CER calculation results
Scoring and review criteria
Test data is added gradually after quality and licensing conditions are reviewed. The latest test list and results are available on the benchmark page.
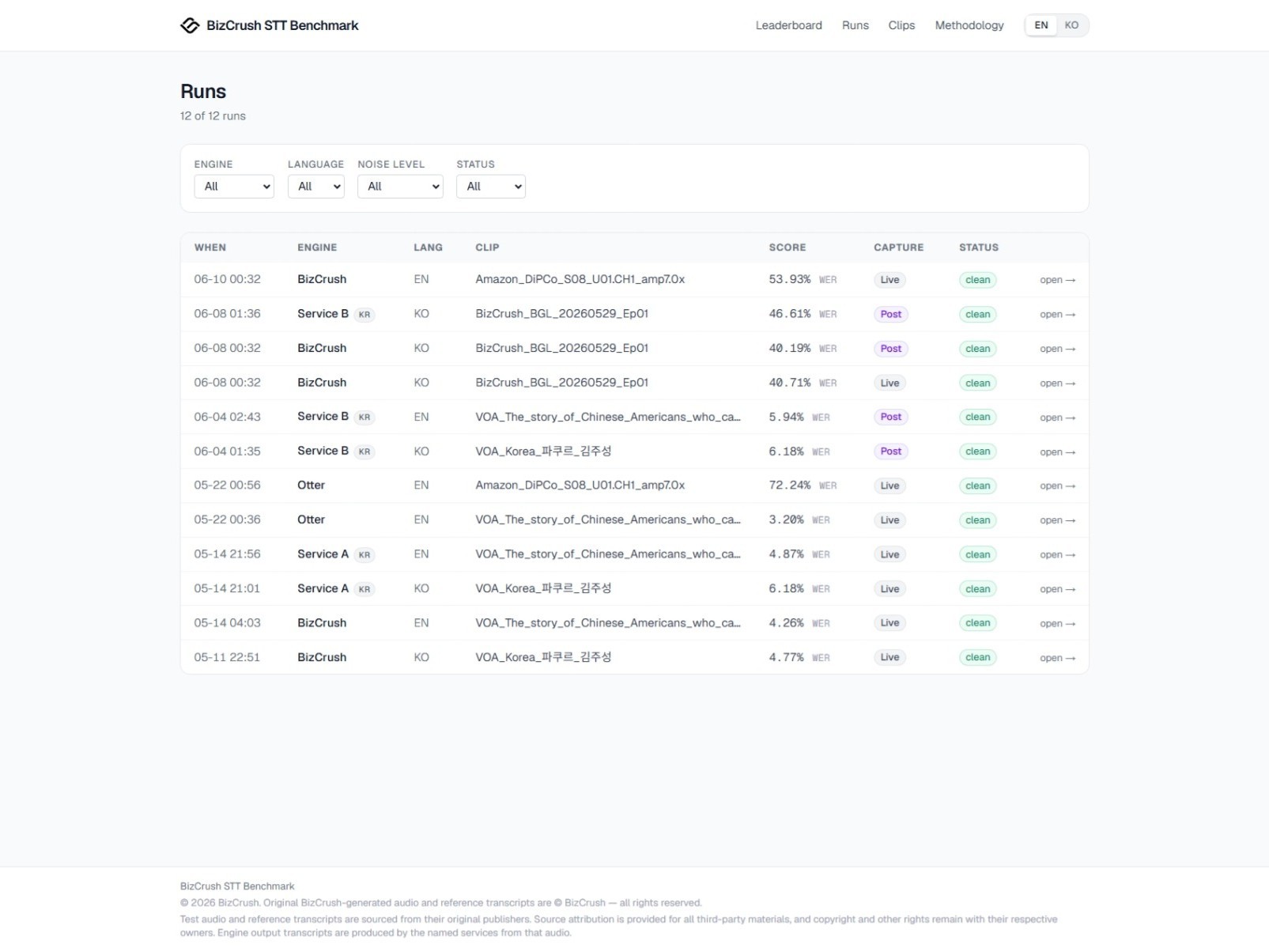
June 12, 2026. The runs page layout may change in future updates.
Transparency and usage limitations
All public tests include the source audio, reference transcript, app-generated transcript, error analysis, and WER/CER calculation results.
This allows readers to inspect the results directly on the page and recalculate them if needed.
Some comparison services may be anonymized when necessary. The purpose is not to identify or criticize specific vendors, but to compare actual outputs under the same conditions. Even when a service is anonymized, the same input, scoring criteria, and disclosure rules apply.
Source audio can be reviewed directly on each benchmark page. However, to prevent unauthorized saving, redistribution, or reuse, audio file downloads are not provided.
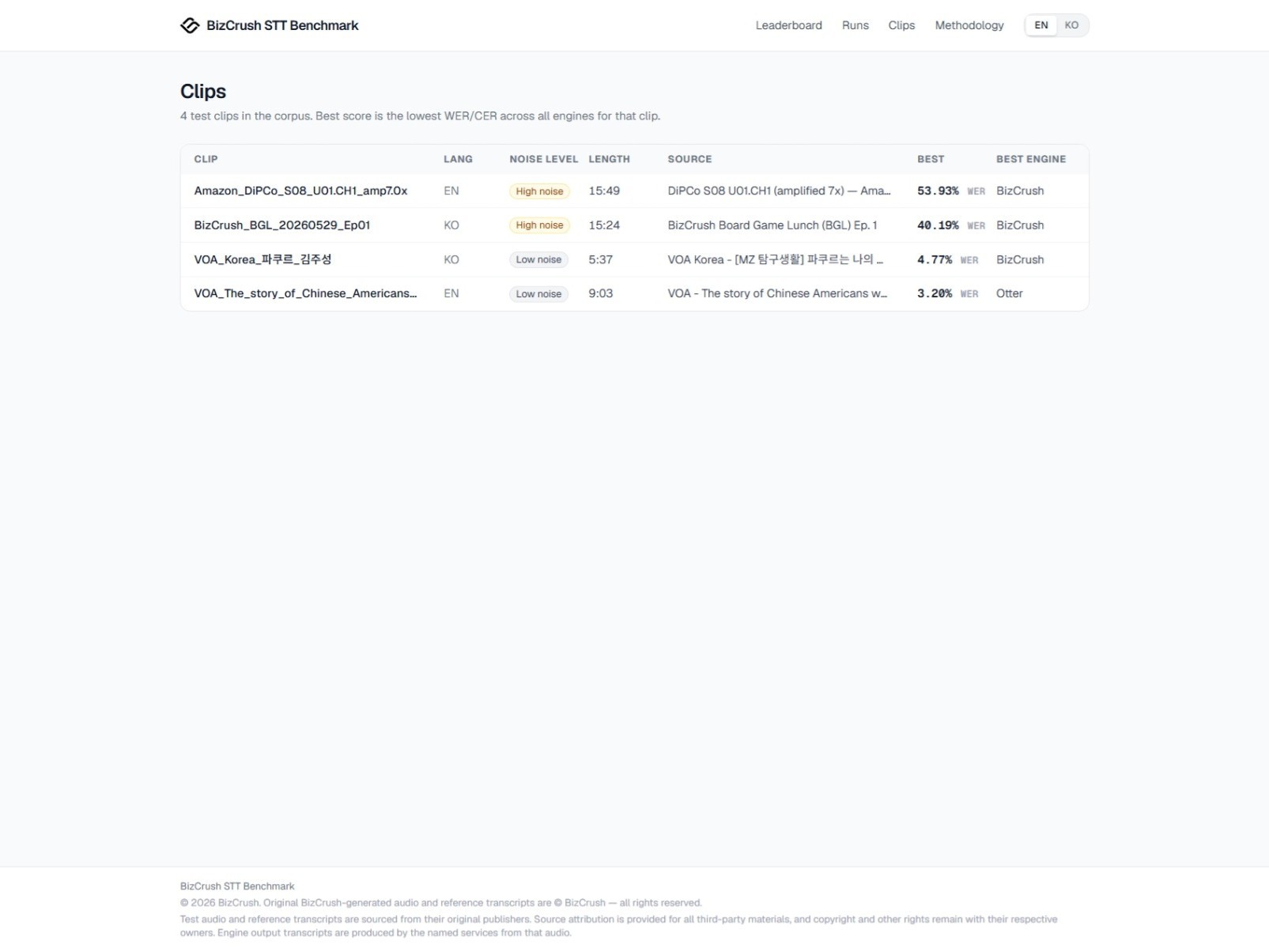
June 12, 2026. Please visit the benchmark page for the latest test list and results.
For third-party source audio, we provide links to the original materials where applicable. BizCrush-produced test data is made available for on-page verification only. Unauthorized saving, redistribution, or reuse is not permitted. If a school, research institution, company, or any external organization would like to use the data, please contact BizCrush for separate approval.
How to interpret the results
This benchmark does not represent every possible real-world environment. Actual results may vary depending on the device, microphone quality, network conditions, app version, speaker position, room acoustics, and type of background noise.
The BizCrush Benchmark should therefore be read as a same-condition comparison, not as a universal measure of performance in every environment.
A single score is not the whole story. It is also important to look at where errors occur, what type of errors they are, and how the app output compares with the source audio and reference transcript. That is why BizCrush publishes the score together with the audio, transcript, and error analysis.
What’s next
The current benchmark focuses on app-based testing. Going forward, we plan to add:
More diverse noise conditions
Direct API testing
More language coverage
Direct API testing will be added as a complementary view, not as a replacement for app-based testing. It will help show the difference between engine-level performance and the app experience users actually see.
We also plan to expand language coverage over time. However, each language requires reliable reference transcripts and a review process that can be applied consistently. Rather than adding languages for the sake of volume, we will expand in a way that keeps the data inspectable and reliable.
A useful benchmark starts with trustworthy data built over time. BizCrush will continue developing STT evaluation criteria that stay close to how people actually use transcription apps.

